Practical Pilot Deployments with AI Cost Firewall v0.1.9
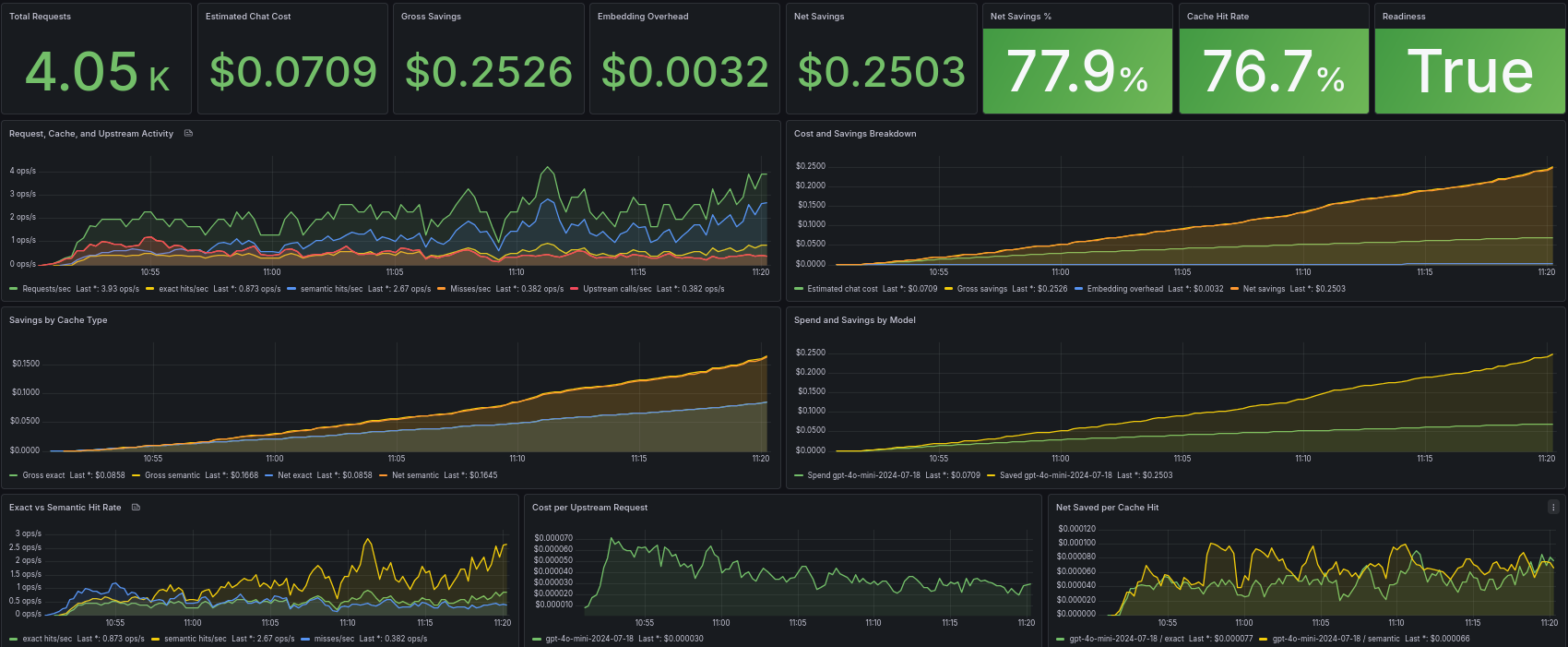
AI Cost Firewall began as a lightweight OpenAI-compatible gateway designed to reduce LLM cost and latency through exact and semantic caching. Over time, the project evolved beyond simple request reuse and gradually became a broader operational layer for AI infrastructure.
Recent releases introduced semantic cache lifecycle management, provider flexibility, improved Prometheus and Grafana observability, configuration diagnostics, and detailed cost accounting. Those features improved the technical capabilities of the system significantly, but another important question remained:
How quickly can somebody actually deploy and evaluate the system in a real environment?
That question became the main focus of v0.1.9.
Unlike earlier releases that concentrated on internal infrastructure features, v0.1.9 focuses primarily on operational polish. The goal of this release is to reduce the friction between discovering the project and successfully running it with dashboards, cache reuse, and observable semantic behavior.
In practice, this means clearer deployment patterns, better onboarding, improved startup diagnostics, more actionable provider error messages, and significantly expanded operational documentation.