Why Edge AI Benefits from Small Rust Binaries

When people talk about Edge AI, the conversation usually revolves around models. Larger context windows, smaller quantized variants, GPU acceleration, inference speed, and hardware optimization tend to dominate the discussion. But in practice, many real-world Edge AI deployments are constrained not by the model itself, but by the operational realities surrounding it.
Running AI at the edge means running software in environments that are fundamentally different from modern cloud infrastructure. These systems may operate with limited memory, modest CPUs, unreliable connectivity, restricted storage, or strict uptime requirements. They may be installed in factories, telecom cabinets, or remote locations where updates are difficult and maintenance windows are limited.
In these environments, the infrastructure surrounding the AI model becomes critically important.
Inference alone is rarely enough. Real systems require routing, telemetry, caching, authentication, observability, synchronization, and APIs to name a few. As Edge AI deployments mature, the supporting software stack increasingly determines whether the system remains practical to operate over time.
This is where small Rust binaries become unexpectedly valuable.
A simplified comparison illustrates how deployment characteristics differ between traditional runtime-heavy stacks and lightweight Rust-based infrastructure.
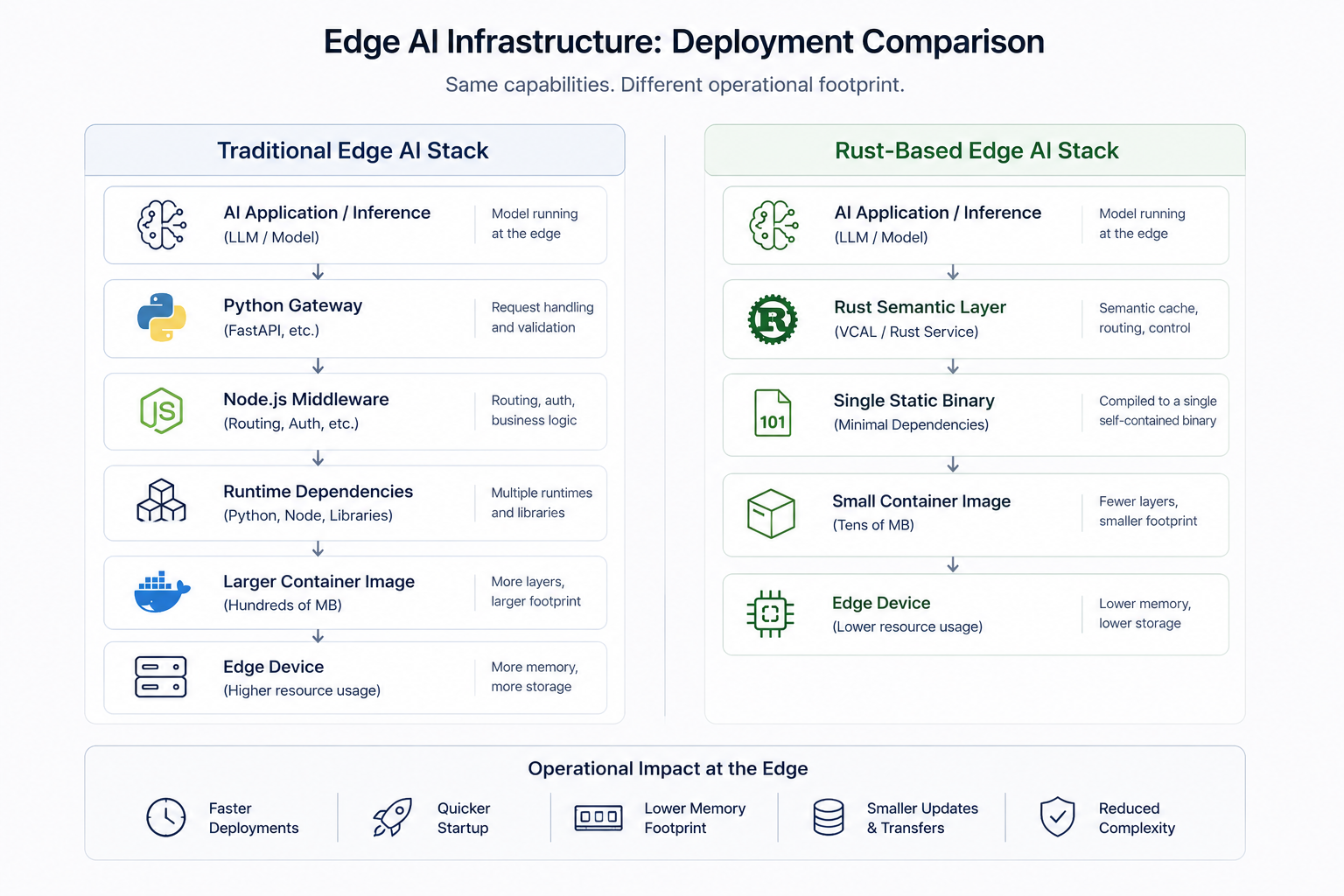
A great deal of modern AI infrastructure is assembled from heavyweight runtime environments. Python services, Node.js middleware, layered containers, package managers, dynamically linked dependencies, and multiple supporting sidecars work reasonably well in large cloud environments where storage, memory, and compute resources are abundant. Cloud-native ecosystems are optimized around this assumption.
Edge systems operate under very different constraints.
A deployment that feels trivial in Kubernetes can become fragile when moved into a constrained ARM device or an industrial Linux gateway. Every additional runtime layer increases image size, startup complexity, memory overhead, update time, and operational surface area. In disconnected or bandwidth-constrained environments, even transferring updates can become an engineering problem.
The difference between a small statically linked binary and a multi-hundred-megabyte container image is not merely aesthetic. It changes how systems behave operationally.
Rust fits this environment unusually well because it combines low-level efficiency with modern software engineering practices. Rust applications can achieve native performance while maintaining memory safety without relying on garbage collection. They can often be compiled into small standalone binaries with minimal runtime dependencies, especially when using musl-based static builds.
Operationally, this has several consequences.
Deployment becomes simpler because the application can often be distributed as a single executable without requiring external runtimes or complex dependency trees. Updating edge systems becomes faster because smaller artifacts transfer more efficiently across constrained networks. Startup times improve because the system avoids initializing large runtime environments. Memory consumption remains relatively predictable, which matters when multiple services must coexist on limited hardware.
Perhaps more importantly, the operational model itself becomes easier to reason about.
In edge environments, reliability frequently depends on reducing complexity rather than adding abstraction. A smaller deployment footprint generally means fewer moving parts, fewer compatibility problems, fewer patching requirements, and fewer failure scenarios. This becomes increasingly important in industrial or regulated environments where operational stability matters more than developer convenience.
Static linking is one of the more underrated aspects of this approach. A fully self-contained binary changes deployment from “install and configure an environment” into something much closer to “copy and run.” That may sound simplistic, but at scale, simplicity becomes an operational advantage. Especially in disconnected or semi-connected infrastructure, reducing environmental assumptions can significantly improve reliability.
Edge AI also introduces another practical challenge: repeated computation.
Many edge systems process highly repetitive workloads. Similar prompts, recurring semantic queries, repeated retrieval patterns, and predictable operational workflows appear constantly in production environments. Without an intermediate control layer, these systems repeatedly recompute results they have effectively already seen before.
This creates unnecessary pressure on hardware resources that are already constrained.
Semantic caching becomes particularly useful at the edge because compute resources are finite and expensive. Reducing repeated inference can improve responsiveness, lower latency, decrease hardware utilization, and reduce energy consumption. In disconnected environments, lightweight caching layers can also help systems remain responsive even when upstream connectivity is unstable or unavailable.
This is one reason why we believe lightweight infrastructure matters just as much as lightweight models.
At VCAL Labs, we have been building semantic infrastructure components in Rust not only because of performance characteristics, but because operational portability increasingly matters in AI systems. Small binaries, predictable resource usage, and minimal deployment friction align naturally with the realities of edge environments.
The future of Edge AI will likely depend on more than just advances in inference itself. It will also depend on whether the surrounding infrastructure can operate reliably in constrained, distributed, and operationally complex environments.
In many cases, the hardest problem is not running the model once.
The harder problem is continuously operating the systems around it.
Observability, routing, semantic caching, synchronization, APIs, telemetry, and traffic control all become part of the deployment surface. And as AI infrastructure moves closer to the edge, operational efficiency starts to matter just as much as raw model capability.
Small Rust binaries are not a universal solution to these problems. But they are remarkably well aligned with the operational realities of Edge AI infrastructure, and that alignment is becoming increasingly difficult to ignore.
Learn more about VCAL semantic infrastructure for AI systems: https://vcal-project.com/